BigCode, from research to product—an open innovation case study
admin
May 23, 2024
ServiceNow Research
References to “we” in this post should be considered the collective efforts of the BigCode community.
Finding practical applications and concrete use cases for AI research often entails multidisciplinary business teams “crossing the valley of death”—a long and arduous process of exploration, experimentation, de-risking, and uncertainty, where projects have a high degree of languishing risk before they’re finished.
This challenge was no different for the BigCode project, an open-scientific collaboration stewarded by ServiceNow and Hugging Face. The project for the responsible development and use of large language models (LLMs) for code, empowering machine learning (ML) and open-source communities through open governance, was something never attempted before at ServiceNow.
Prequel
As a company, ServiceNow takes a hybrid approach to innovation. We actively lead and participate in open scientific collaborations: with leading academic institutions and organizations on fundamental research; through the AI Lighthouse customer-centric innovation program to fast-track the development and adoption of generative AI; and of course, advancing the state of the art in enterprise AI with innovations for the Now Platform.
The idea for BigCode arose during conversations in Utrecht, the Netherlands, between Harm de Vries from ServiceNow Research and Thomas Wolf from Hugging Face. Both were inspired by the approach and success of the BigScience “Summer of Language Models 21” one-year workshop on LLMs for research.
Building off the best practices from BigScience, the BigCode community was formed to focus on the development of open LLMs for code, guided by the stated principle of responsible development and conducted with open governance. To jump-start BigCode, ServiceNow and Hugging Face committed to providing:
Resources for research and scientific community leadership
Compute for model training
Code to support data preparation
Code to enable model training
Model weights
A large dataset of open-source code for the community to evaluate and prepare for LLM pretraining
Toward healthier ML and open-source software
BigCode officially started in September 2022, when we announced the project. We held the first public webinar on Oct. 6, 2022, with the aim to excite and rally the community around the project mission and vision.
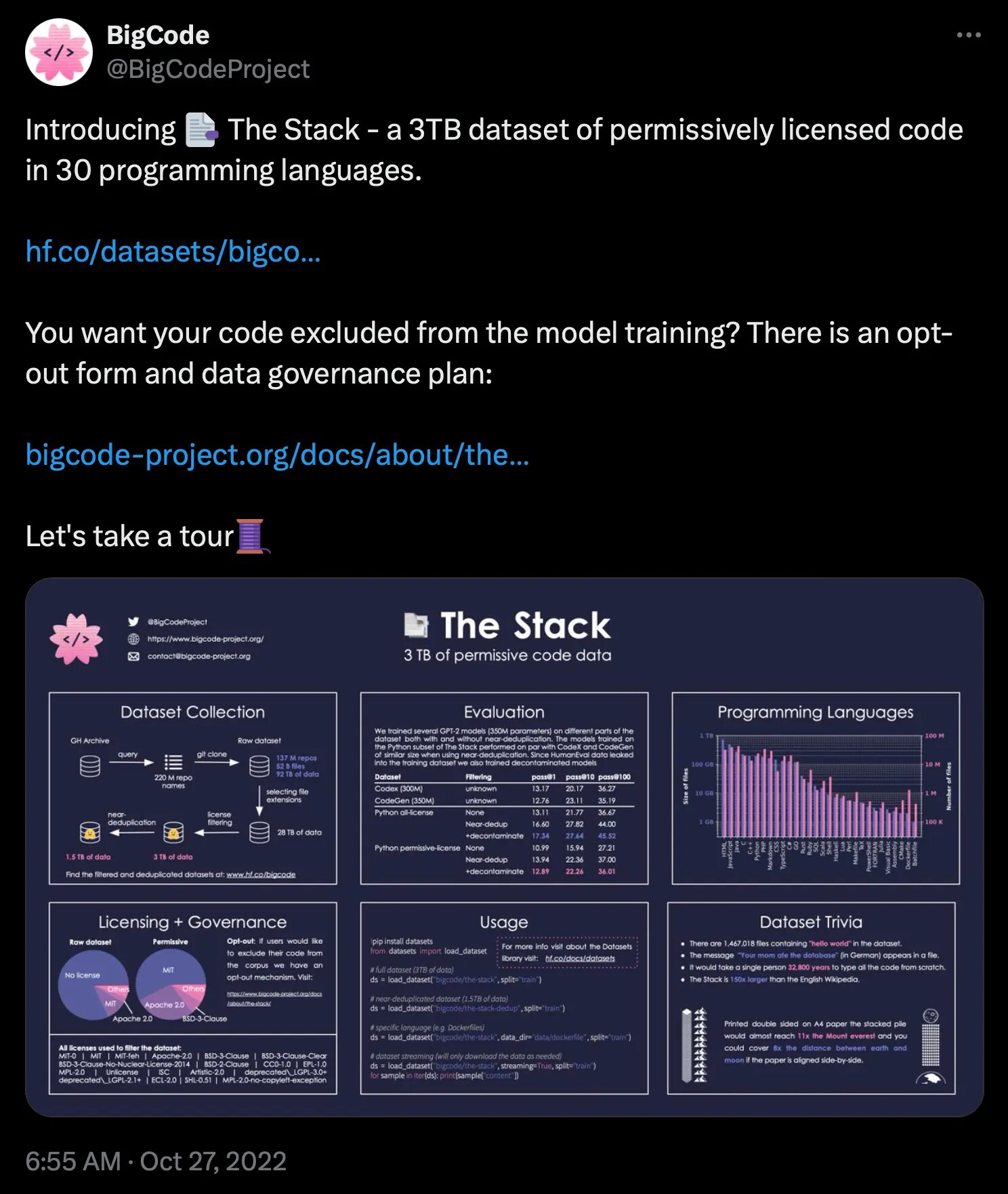
On Oct. 27, 2022, we released The Stack—a dataset containing 3TB of permissively licensed source code with minimal restrictions on how the software could be copied, modified, and redistributed. We took the unprecedented step of also providing developers who had previously published permissively licensed open-source software to opt out of having their data used to train models.
This first dataset release was extraordinary. With additional support from the extended legal-tech community, we released The Stack v1.1 on Dec. 1, 2022. It more than doubled in size to include 6.4TB of permissively licensed data, spanning 358 programming languages and 193 permissive license types.
As covered in the BigCode project governance card, The Alan Turing Institute and the Turing Way conducted open-source community feedback research and workshops in early 2023 to find out how the wider community felt about their data being used in The Stack for training code LLMs. The research included two open, international workshops: Open Data Day 2023 and Mozilla Festival (MozFest) 2023, with a session titled “Designing for Data Rights in the AI Production Pipeline.”
Through those efforts, we learned that when it comes to governance of LLM datasets, participants feel it’s better to both know about and have a choice in their data being included. This reinforced commitment to our approach with The Stack, Am I in The Stack, and our opt-out mechanism.
SantaCoder
On Dec. 22, 2022, we released the first model: a 1.1-billion-parameter code LLM called SantaCoder, trained on Python, Java, and JavaScript from The Stack v1.1. At the time, SantaCoder outperformed much larger open-source models on both left-to-right generation and infilling.
The open-source community annotated 400 samples of code with examples of sensitive personally identifiable information (PII)—such as email addresses, secret keys, and IP addresses—and then built and continuously refined regular-expression rules to remove the information from the pretraining dataset before training any models.
StarEncoder and StarPII
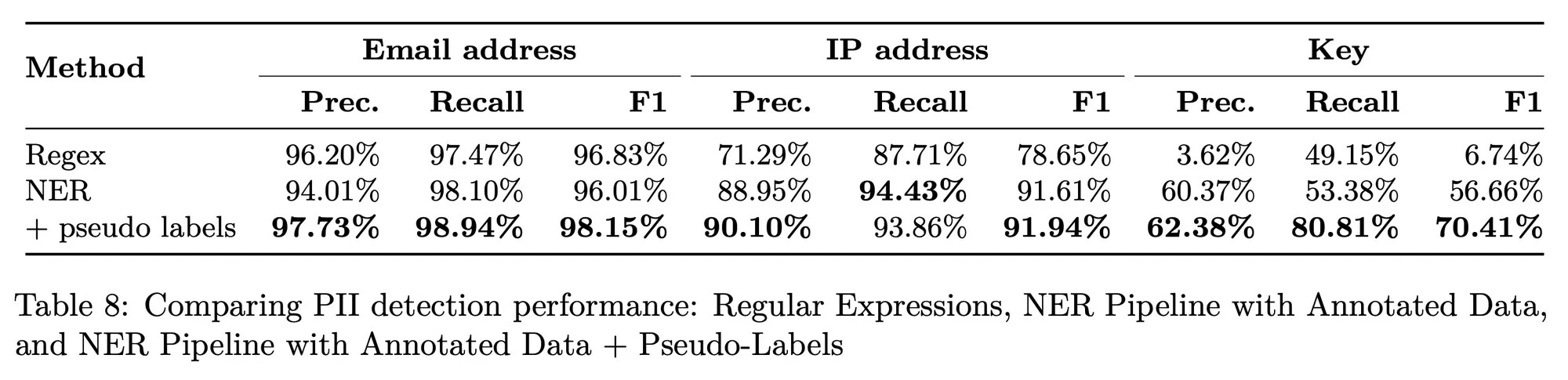
To improve the detection of PII in code data, we selected 12,000 code samples from The Stack and annotated them wherever we found examples of PII. The annotators detected a total of 22,950 PII entities in the resulting BigCode PII dataset.
As part of our PII detection efforts, we trained an encoder-only model, StarEncoder, which can be efficiently fine-tuned for both code- and text-related tasks. We then fine-tuned StarEncoder on the PII-annotated dataset for the named entity recognition (NER) task. We added a linear layer as a token classification head on top of the encoder model, with six target classes:
Names
Emails
Keys
Passwords
IP addresses
Usernames
Performance of the resulting StarPII NER model is reflected in Table 8 of the StarCoder paper:
StarCoderBase: Trained on 80+ languages from The Stack
StarCoder: StarCoderBase further trained on Python
StarCoderPlus: StarCoderBase further trained on English web data
The StarCoder models are 15.5-billion-parameter models trained on more than 80 programming languages from The Stack (v1.2), with opt-out requests excluded. The model uses Multi-Query Attention, a context window of 8,192 tokens, and was trained using the fill-in-the-middle (FIM) objective on 1 trillion tokens.
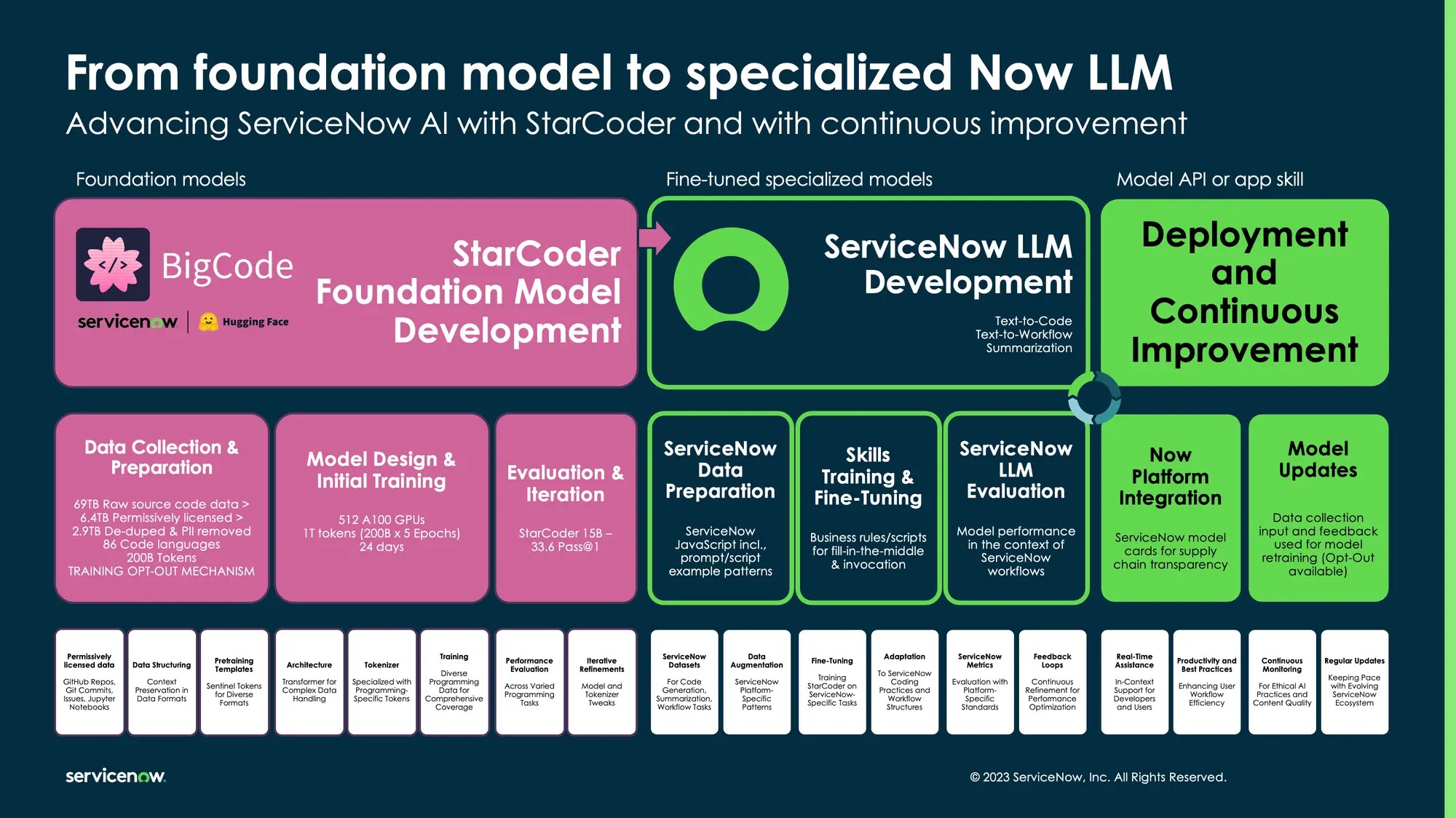
From research to product at scale
At the time of writing, ServiceNow has adopted three models from the StarCoder family. These LLMs were fine-tuned on workflow data from the ServiceNow platform and from ServiceNow scripting best practices to power the Now Assist generative AI skills for users of the platform.
These include the ServiceNow summarization LLM to power the case resolution notes, task summarization, and chat summarization Now Assist skills; the ServiceNow text-to-code LLM to power the scripting code assistant skill; and the ServiceNow text-to-workflow LLM for workflow assistant skill.
A high-level overview of the end-to-end AI software development lifecycle, from research to production at scale, showcasing the creation of the StarCoder foundation model to creating the ServiceNow fine-tuned Now LLMs and serving the models through the Now Platform to power Now Assist generative AI skills
StarCoder adoption and real world impact
While code generation and autocomplete are common capabilities found in code LLMs, StarCoder’s implementation and performance with FIM really sets it apart. Sourcegraph reports that StarCoder has a code completion acceptance rate of 30%.
VMware fine-tuned StarCoder to learn VMware’s preferred coding style and created a small parameter-efficient fine-tuning (PEFT) model of 150MB (base StarCoder is 70GB). ServiceNow reports that the text-to-code and text-to-workflow LLMs fine-tuned from StarCoder help boost ServiceNow developer productivity and speed of innovation by 52%.
An example of Now Assist for Creator powered by the ServiceNow text-to-code LLM based on StarCoder being used to generate advanced scripts for custom business rules
Transparency and responsibility at the heart
Focusing on openness is good for society and the future. Transparency of foundation models is declining just as their societal impact is rising, according to the Stanford University Center for Research on Foundation Models (CRFM) Foundation Model Transparency Index. “If this trend continues, foundation models could become just as opaque as social media platforms and other previous technologies, replicating their failure modes,” CRFM adds.
BigCode focuses on three areas of social impact: privacy, security, and the consent of data subjects. We found that while these considerations did sometimes result in trade-offs between the performance goals and social impact concerns, they were more often better addressed by developing new technical and organizational tools.
StarCoder models were released under an open and responsible AI model license agreement (BigCode OpenRAIL-M v1.0), which enables royalty-free access and flexible use and sharing of it while setting specific-use restrictions for certain critical scenarios. For users who want to share the model, we require similar use restrictions and a similar model card.
Organizing collaborations
BigCode is governed by a steering committee jointly led by ServiceNow and Hugging Face. More than 1,200 members from institutions and companies across 62 countries have given their time and resources to help the project succeed. In addition, a handful of dedicated resources from both Hugging Face and ServiceNow sped up the process. We estimate the time commitment corresponded to six full-time employees from the host institutions since the project began.
Our governance structure, with the committee making the final decisions, helps us streamline decision-making processes and informs contributors about their role in governance. BigCode is a research collaboration and is open to participants who have a professional research background and are able to commit time to the project. We’re still inviting AI researchers to work with us on continuing our mission.
Recently, together with Hugging Face and NVIDIA, ServiceNow trained three new models and announced StarCoder2 and The Stack v2, which are trained with four times more data than the original StarCoder, with data from Software Heritage. We look forward to seeing what the community builds from these releases.